




Hard skills are technical, measurable abilities like advanced programming, data modeling, and database management that ensure efficient data processing and storage solutions.
Data Engineer Resume Examples & Templates
Looking to boost your career as a data engineer? Our data engineer resume examples highlight essential skills like data modeling and ETL processes, helping you stand out to potential employers.

by Gabriela Hernandez, Last Updated: January 18, 2026
Hired By:*

- Popular Data Engineer Resume Examples
- Resume Template—Easy to Copy & Paste
- Build Your Resume in Minutes
- How to Write a Data Engineer Resume Summary
- Showcasing Your Work Experience
- Top Skills to Include on Your Resume
- Resume Format Examples
- Related Engineering Resume Examples
- Frequently Asked Questions
- Should I include a cover letter with my data engineer resume?
- Can I use a resume if I’m applying internationally, or do I need a CV?
- What soft skills are important for data engineers?
- I’m transitioning from another field. How should I highlight my experience?
- Where can I find inspiration for writing my cover letter as a data engineer?
- Should I include a personal mission statement on my data engineer resume?
Popular Data Engineer Resume Examples
Discover our top data engineer resume examples that showcase key skills such as data modeling, ETL processes, and big data technologies. These examples will help you effectively present your qualifications to potential employers.
Are you ready to build your standout resume? Our Resume Builder offers user-friendly templates designed specifically for data professionals, simplifying the process of highlighting your expertise.
Recommended
 Customize This Resume
Customize This ResumeEntry-level data engineer resume
What this resume does well:
This entry-level resume for a data engineer effectively highlights the applicant's technical skills and significant accomplishments, such as optimizing SQL queries and managing large data pipelines. New professionals in this field must show their ability to handle complex data challenges and demonstrate relevant projects or internships that reflect their competence despite having limited professional experience.
Mid-career data engineer resume
What this resume does well:
This resume effectively showcases the job seeker's qualifications through a clear presentation of accomplishments and responsibilities. The progression from data analyst to data engineer illustrates a solid foundation in data management, highlighting readiness for advanced challenges and leadership roles in the field.
Experienced data engineer resume
What this resume does well:
This resume demonstrates the applicant's strong data engineering background, highlighting their achievements such as optimizing data pipelines by 35% and maintaining cloud infrastructure to save $20K annually. The bullet-point format improves readability, making it easy for hiring managers to quickly grasp key accomplishments.
Resume Template—Easy to Copy & Paste
Example
David Liu
Chicago, IL 60607
(555)555-5555
David.Liu@example.com
Professional Summary
Accomplished Data Engineer with a track record of optimizing data systems and enhancing efficiency, skilled in ETL processes and cloud solutions, seeking to drive data innovation at forward-thinking companies.
Work History
Data Engineer
AI Solutions Group - Chicago, IL
May 2023 - October 2025
- Optimized ETL processes by 40%
- Reduced data latency by 15ms
- Deployed scalable data pipelines
Database Developer
Innovate Tech Corp - Chicago, IL
May 2021 - April 2023
- Designed databases boosting efficiency by 25%
- Automated data validation procedures
- Improved query performance by 30%
Data Architect
InfoTech Systems - Springfield, IL
May 2020 - April 2021
- Developed data models increasing accuracy by 20%
- Led team of 4 engineers on data projects
- Standardized data formats across systems
Skills
- ETL Development
- Data Modeling
- SQL Optimization
- Data Pipeline Building
- AWS Cloud Services
- Big Data Analytics
- Python Programming
- Machine Learning Algorithms
Education
Master of Science Computer Science
Stanford University Stanford, California
June 2020
Bachelor of Science Information Systems
University of California, Berkeley Berkeley, California
June 2018
Certifications
- Certified Data Engineer - Big Data Association
- AWS Certified Solutions Architect - Amazon Web Services
Languages
- Spanish - Beginner (A1)
- Mandarin - Beginner (A1)
- French - Intermediate (B1)
Build Your Resume in Minutes
Creating a custom resume is easier than ever with our Resume Builder!

How to Write a Data Engineer Resume Summary
Your resume summary is the first impression employers will have of you, making it important to capture their attention quickly. As a data engineer, you should highlight your technical skills in data processing, database management, and analytical problem-solving.
Focus on showcasing your experience with big data technologies and your ability to improve data flow efficiency. This section serves as a snapshot of your professional background that can set you apart from other job seekers.
To illustrate what makes an effective resume summary for this role, we will provide some examples that highlight best practices and common pitfalls to avoid:
Weak Example
I am a data engineer with several years of experience in the field. I am seeking a position that allows me to use my skills to help the company succeed. A job that offers good hours and chances for advancement is what I want. I believe I can be an asset to your team if you consider my application.
Why this summary misses the mark:
- Lacks specific details about technical skills or projects, making it too vague
- Overuses personal language and fails to convey concrete contributions to potential employers
- Emphasizes job seeker’s desires rather than demonstrating value they can deliver to the organization
Strong Example
Results-driven data engineer with 6+ years of experience in designing and implementing scalable data solutions. Achieved a 30% improvement in data processing times by optimizing ETL workflows and leveraging cloud technologies. Proficient in SQL, Python, and big data frameworks such as Hadoop and Spark, ensuring efficient data management and analysis.
Why this summary works:
- Starts with clear experience level and area of expertise
- Highlights quantifiable achievements that showcase significant improvements in performance metrics
- Includes relevant technical skills that align with industry demands for data engineering positions
Pro Tip
If you’re new to the data engineering field, consider using a career objective on your resume. This approach highlights your goals and enthusiasm rather than focusing on limited experience. Check out tailored resume objective examples to help you craft your own unique statement.
Showcasing Your Work Experience
The work experience section is important for your resume as a data engineer, serving as the primary focus where you'll present most of your content. Good resume templates emphasize this section to help you stand out.
This area should be structured in reverse-chronological order, listing your past roles clearly. Use bullet points to detail your specific achievements and contributions in each job held.
To illustrate effective work history entries for data engineers, we will share a couple of examples that highlight what works well and what pitfalls to avoid:
Weak Example
Data Engineer
Tech Solutions LLC – San Francisco, CA
- Managed data storage and retrieval processes.
- Wrote code for data manipulation tasks.
- Collaborated with team members on projects.
- Monitored system performance and resolved issues.
Why this work experience section misses the mark:
- No details about the employment dates
- Bullet points are overly simplistic and lack specifics on achievements
- Focuses on routine tasks rather than highlighting effective contributions
Strong Example
Data Engineer
Tech Solutions Inc. – San Francisco, CA
March 2021 - Present
- Design and implement scalable data pipelines that improve data processing efficiency by 40%.
- Collaborate with data scientists to optimize machine learning models, improving prediction accuracy by 30%.
- Develop automated reporting tools that reduced manual reporting time by 50%, allowing for more strategic decision-making.
Why this work experience section works:
- Starts each bullet point with compelling action verbs that clearly convey the job seeker’s contributions
- Incorporates specific metrics to quantify achievements and demonstrate effectiveness
- Highlights relevant technical skills alongside accomplishments, showcasing the job seeker’s expertise in the field
While the resume summary and work experience are important parts of your application, don’t overlook other important sections that deserve careful formatting. For additional expert insights, be sure to check out our complete guide on how to write a resume.
Top Skills to Include on Your Resume
A skills section is important for any powerful resume as it provides a snapshot of your qualifications. This area allows hiring managers to quickly identify if you possess the essential competencies for the data engineer role.
In this profession, it's important to highlight both technical skills and analytical abilities. Be sure to include tools like SQL, Python, and Hadoop, along with your familiarity with cloud platforms such as AWS or Azure.
Soft skills are interpersonal qualities like problem-solving, communication, and teamwork that facilitate collaboration and innovation in complex data environments.
Selecting the right resume skills is important to meet employer expectations and pass automated screening systems. Many organizations use software that filters out applicants lacking essential qualifications for the position.
To improve your chances of success, review job postings carefully since they often highlight the key skills employers seek. This can help you tailor your resume to attract both recruiters and ATS systems alike.
Pro Tip
Ensure your resume stands out and gets noticed by applicant tracking systems. Use our ATS Resume Checker to discover over 30 common pitfalls and improve your chances of landing that data engineer role.
10 skills that appear on successful data engineer resumes
Make your resume stand out to recruiters by highlighting key skills that are highly sought after in data engineering roles. You can see these skills in action within our resume examples, which help you apply confidently to your next opportunity.
Here are 10 essential skills you should consider including in your resume if they align with your experience and job needs:
Sql expertise
Etl development
Data migration
Data warehousing
Data pipeline design
Data modeling
Performance tuning
Big data processing
Metadata management
Api development
Based on analysis of 5,000+ engineering professional resumes from 2023-2024
Resume Format Examples
Selecting the appropriate resume format is important for a data engineer, as it showcases your technical skills, relevant experience, and career advancements in a clear and compelling way.
Entry-Level 0 - 2 years
Functional
Focuses on skills rather than previous jobs
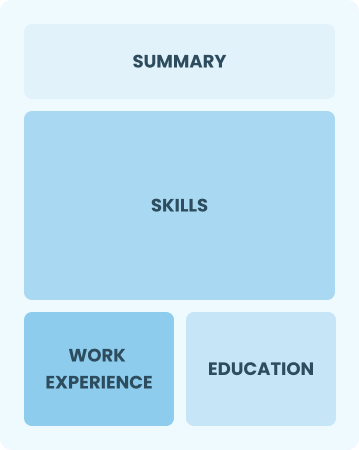
Best for:
Recent graduates and career changers with up to two years of experience
Mid-Career 3 - 7 years
Combination
Balances skills and work history equally
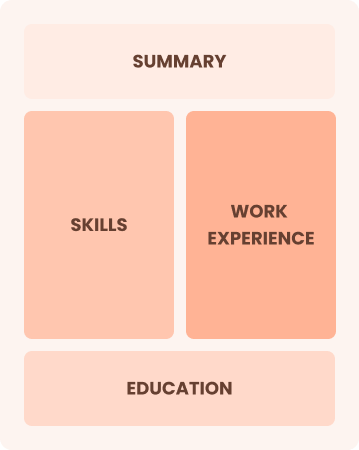
Best for:
Mid-career professionals focused on demonstrating their skills and growth potential
Experienced 8+ years
Chronological
Emphasizes work history in reverse order

Best for:
Seasoned data engineers leading innovative projects and optimizing systems
Frequently Asked Questions
Should I include a cover letter with my data engineer resume?
Absolutely! A cover letter can significantly boost your application by showcasing your personality and providing deeper insight into your skills. It allows you to connect the dots between your experience and the job requirements. If you're looking for guidance, check out our how to write a cover letter guide or use our Cover Letter Generator to craft a compelling letter quickly.
Can I use a resume if I’m applying internationally, or do I need a CV?
When applying for jobs internationally, use a CV instead of a resume to provide a comprehensive overview of your academic and professional history. To assist you, we offer various resources that outline how to write a CV, including proper formatting and creation strategies tailored to different regions. Additionally, explore our selection of CV examples for inspiration in crafting an effective document.
What soft skills are important for data engineers?
Soft skills like communication, collaboration, and problem-solving are essential for data engineers. These interpersonal skills facilitate effective teamwork and help translate complex technical concepts to non-technical stakeholders, ultimately driving project success and innovation within the organization.
I’m transitioning from another field. How should I highlight my experience?
Highlight transferable skills such as analytical thinking, teamwork, and programming knowledge from previous jobs. These abilities illustrate your readiness to tackle data engineering challenges, even if your background isn't in tech. Use concrete examples to relate your past successes to key responsibilities in data engineering roles.
Where can I find inspiration for writing my cover letter as a data engineer?
When crafting your cover letter for data engineer positions, consider exploring cover letter examples. These samples provide valuable inspiration for content ideas, formatting tips, and showcasing your qualifications effectively. They can help you present your skills in a compelling way that stands out to employers.
Should I include a personal mission statement on my data engineer resume?
Including a personal mission statement on your resume is advisable. It effectively conveys your core values and career aspirations, which can be especially beneficial when applying to organizations that prioritize innovation and data-driven decision-making within their culture.

Ready to land the job?
Join 28M+ others who've built a resume that works.



