




Technical competencies, such as network management, cybersecurity protocols, and software development, are hard skills that an IT manager must possess to effectively oversee technology operations.
IT Manager Resume Examples & Templates
Ready to elevate your career? Our IT manager resume examples showcase essential skills like project management and team leadership to help you stand out to potential employers.

by Gabriela Hernandez, Last Updated: January 29, 2026
Hired By:*

- Popular IT Manager Resume Examples
- Resume Template—Easy to Copy & Paste
- Build Your Resume in Minutes
- How to Write a IT Manager Resume Summary
- Showcasing Your Work Experience
- Top Skills to Include on Your Resume
- Resume Format Examples
- Related Information Technology (IT) Resume Examples
- Frequently Asked Questions
- Should I include a cover letter with my IT manager resume?
- Can I use a resume if I’m applying internationally, or do I need a CV?
- What soft skills are important for IT managers?
- I’m transitioning from another field. How should I highlight my experience?
- Where can I find inspiration for writing my cover letter as an IT manager?
- Should I include a personal mission statement on my IT manager resume?
Popular IT Manager Resume Examples
Discover our top IT manager resume examples that emphasize key skills such as project management, team leadership, and technical expertise. These examples demonstrate how to effectively showcase your accomplishments to potential employers.
Are you ready to build your ideal resume? Our Resume Builder offers user-friendly templates specifically designed for IT professionals, helping you create a standout application with ease.
Recommended
 Customize This Resume
Customize This ResumeIT manager resume
What this resume does well:
The resume features clear formatting and a modern resume fonts option that improves readability, allowing key achievements to stand out. Such design choices not only make the document visually appealing but also highlight the job seeker's professionalism, which is important for making a strong impression in the competitive field of IT management.
IT operations manager resume
What this resume does well:
This resume successfully combines key skills such as IT strategy and project management with relevant work experience. By presenting these competencies alongside a proven track record of improving operational efficiency, employers can easily assess the applicant's ability to lead IT initiatives and drive organizational success.
Technology manager resume
What this resume does well:
This resume skillfully uses bullet points to present a wealth of experience clearly and concisely, allowing hiring managers to quickly identify significant achievements. The effective spacing between sections and clear headings improve readability, making it easy to navigate through the applicant's qualifications and successes.
Resume Template—Easy to Copy & Paste
Example
John Rodriguez
Westbrook, ME 04094
(555)555-5555
John.Rodriguez@example.com
Skills
- Project Management
- Cybersecurity
- Cloud Solutions
- Team Leadership
- Budget Management
- Network Optimization
- Systems Analysis
- Technical Support
Certifications
- Certified Information Systems Manager - Global Tech Institute
- Network Security Certification - IT Secure Academy
Languages
- Spanish - Beginner (A1)
- French - Intermediate (B1)
- German - Beginner (A1)
Professional Summary
Dynamic IT Manager optimizing systems for top efficiency. Proven team leadership and cybersecurity skills. Skilled in budget management, cloud solutions, and network optimization.
Work History
IT Manager
Tech Solutions Corp - Westbrook, ME
November 2023 - November 2025
- Led IT projects under budget by 20%
- Reduced response time by 30%
- Supervised team of 15 IT professionals
Technology Operations Head
InnoTech Innovations - Westbrook, ME
June 2022 - October 2023
- Enhanced system uptime to 99.9%
- Managed IT budget of 2 million
- Optimized network security protocols
IT Infrastructure Supervisor
DataStream Solutions - Westbrook, ME
November 2021 - May 2022
- Implemented cloud solutions, saving 20% cost
- Oversaw setup of 200+ workstations
- Trained team for improved service delivery
Education
Master's in Information Technology Information Technology
University of Technology Boston, MA
May 2021
Bachelor's in Computer Science Computer Science
State College Seattle, WA
May 2019
Build Your Resume in Minutes
Creating a custom resume is easier than ever with our Resume Builder!

How to Write a IT Manager Resume Summary
Your resume summary is important as it’s the first impression employers have of you. It sets the tone for your application and can highlight why you stand out as an IT manager.
As an IT manager, you should emphasize your leadership skills, technical expertise, and successful project management experiences. This section is your opportunity to showcase how you've driven innovation and efficiency in past roles.
To guide you in crafting a compelling summary, consider the following examples that illustrate effective strategies and common pitfalls:
Weak Example
I am an experienced IT manager who has worked in various companies. I seek a new position where I can use my skills to help the organization succeed. A company that values teamwork and offers chances for advancement would be perfect for me. I believe I can contribute positively if given the chance.
Why this summary misses the mark:
- Lacks specific examples of achievements or skills relevant to IT management
- Relies heavily on personal pronouns and vague statements, making it less effective
- Emphasizes what the applicant desires rather than highlighting their potential contributions to the employer
Strong Example
Results-driven IT manager with over 7 years of experience in leading technology teams to improve system efficiency and security. Achieved a 30% reduction in system downtime through strategic upgrades and proactive monitoring initiatives. Proficient in cloud computing, network security, and project management methodologies to deliver effective IT solutions aligned with business goals.
Why this summary works:
- Begins with a clear indication of experience level and key responsibilities
- Highlights specific quantifiable achievements that showcase the job seeker's ability to drive performance improvements
- Includes relevant technical skills that are important for the role, demonstrating expertise that potential employers seek
Pro Tip
If formal work experience is missing from your resume, don't stress. Consider using a career objective instead of a summary to highlight your goals and skills. Review tailored resume objective examples to guide you on your journey.
Showcasing Your Work Experience
The work experience section is important for your resume as an IT manager, where you will present the majority of your qualifications. Good resume templates always prioritize this area to showcase your professional journey.
This section should be organized in reverse-chronological order, detailing each position you've held. Highlight your key achievements and contributions in each role using bullet points to make them stand out.
We will provide examples that demonstrate effective writing for an IT manager's work history to further illustrate what works in this section. These examples will clarify what attracts attention and what pitfalls to avoid.
Weak Example
IT Manager
Tech Solutions Inc. – San Francisco, CA
- Oversaw IT projects.
- Managed staff and schedules.
- Maintained computer systems.
- Addressed user issues and provided support.
Why this work experience section misses the mark:
- Lacks specific employment dates to establish timeline
- Bullet points do not highlight any key achievements or metrics
- Vague descriptions fail to demonstrate leadership skills or impact on company operations
Strong Example
IT Manager
Tech Innovations Inc. – San Francisco, CA
March 2020 - Present
- Lead a team of 10 IT professionals to improve system infrastructure, achieving a 30% reduction in downtime through proactive monitoring and maintenance.
- Implemented new cybersecurity protocols that decreased security breaches by 40%, ensuring data integrity and compliance with industry standards.
- Managed a $1 million budget effectively, optimizing resource allocation to support ongoing projects and improve operational efficiency.
Why this work experience section works:
- Starts each bullet with strong action verbs that clearly outline the applicant’s contributions
- Incorporates specific metrics to quantify achievements, making the impact tangible for potential employers
- Highlights key skills relevant to IT management while emphasizing leadership and strategic planning abilities
While your resume summary and work experience are key components, don't overlook the importance of other sections. Each part plays an important role in presenting your qualifications effectively. For detailed guidance, visit our comprehensive guide on how to write a resume.
Top Skills to Include on Your Resume
A skills section is important on your resume as it quickly communicates your technical skills and soft skills to potential employers. It serves as a snapshot of your abilities, allowing hiring managers to assess if you’re a good fit for the IT manager role.
For an IT manager, emphasize both leadership and technical expertise. Mention specific tools like project management software (e.g., JIRA), networking systems, or programming languages (e.g., Python) to show your ability to manage teams and projects effectively.
Essential interpersonal abilities like problem-solving, communication, and leadership are soft skills that foster collaboration within teams and ensure projects align with organizational goals.
When selecting skills for your resume, it's important to align with what employers expect from an ideal job seeker. Many organizations use automated screening systems that filter out applicants lacking essential resume skills.
To effectively capture the attention of recruiters and pass ATS scans, carefully review job postings for specific skill mentions. This approach ensures you highlight relevant abilities that make you a standout applicant in the hiring process.
Pro Tip
Improve your resume to stand out and successfully navigate through applicant tracking systems. Use our ATS Resume Checker to identify over 30 common mistakes, increasing your chances of securing that IT manager role.
10 skills that appear on successful IT manager resumes
Improve your resume to capture the attention of hiring managers by highlighting key skills that are in demand for IT managers. You can find these skills demonstrated in our resume examples, which will help you apply with confidence.
Here are 10 essential skills to consider adding to your resume when they align with your qualifications and job requirements:
Leadership
Project management
Technical skill
Problem-solving
Team collaboration
Budget management
Cybersecurity knowledge
Cloud computing expertise
Data analysis
Vendor management
Based on analysis of 5,000+ information technology (it) professional resumes from 2023-2024
Resume Format Examples
For an IT manager, selecting the appropriate resume format is important as it effectively showcases relevant technical skills, leadership experience, and career advancements in a clear and organized manner.
Entry-Level 0 - 2 years
Functional
Focuses on skills rather than previous jobs
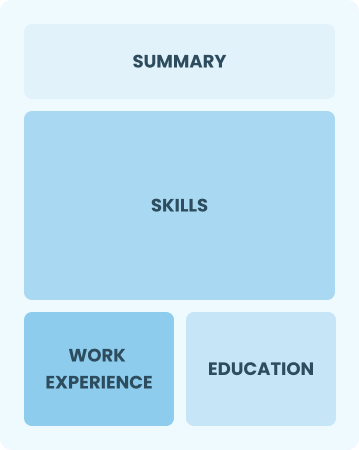
Best for:
Recent graduates and career changers with minimal experience in IT management
Mid-Career 3 - 7 years
Combination
Balances skills and work history equally
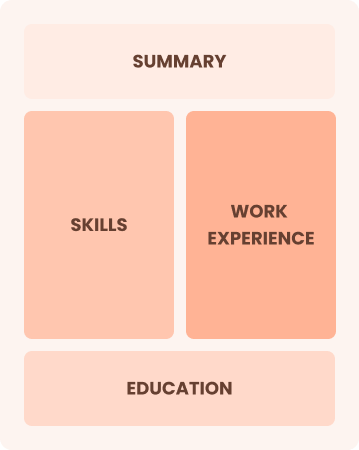
Best for:
Mid-career professionals focused on seeking growth opportunities
Experienced 8+ years
Chronological
Emphasizes work history in reverse order

Best for:
Experienced leaders in IT driving transformative technology solutions
Frequently Asked Questions
Should I include a cover letter with my IT manager resume?
Absolutely, including a cover letter is a great way to showcase your enthusiasm and unique qualifications. A well-crafted cover letter allows you to elaborate on your skills and make a personal connection with potential employers. For tips on writing an effective cover letter, explore our comprehensive guide on how to write a cover letter or use our easy Cover Letter Generator to help create one tailored to your experience.
Can I use a resume if I’m applying internationally, or do I need a CV?
When applying for jobs outside the U.S., use a CV instead of a resume to provide a comprehensive overview of your academic and professional history. To help you format your CV correctly, explore our resources on how to write a CV and review various CV examples tailored for international standards.
What soft skills are important for IT managers?
Soft skills such as communication, problem-solving, and leadership are essential for IT managers. These interpersonal skills foster collaboration within teams and enable effective interactions with stakeholders, ultimately leading to successful project outcomes and a positive work atmosphere.
I’m transitioning from another field. How should I highlight my experience?
Highlight transferable skills like teamwork, strategic planning, and communication from your previous roles. These attributes showcase your ability to lead IT projects and manage teams effectively. Provide concrete examples of how you've solved problems or implemented processes in past jobs to illustrate your readiness for the IT manager role.
Where can I find inspiration for writing my cover letter as an IT manager?
If you're applying for IT manager positions, consider reviewing professionally crafted cover letter examples. These samples provide valuable insights into effective content ideas, formatting tips, and ways to showcase your qualifications in a compelling manner. Let them inspire you to create your standout application materials.
Should I include a personal mission statement on my IT manager resume?
Yes, including a personal mission statement on your resume is recommended. This effectively showcases your values and career aspirations. Including such a statement is particularly beneficial when applying to companies that prioritize innovation and leadership in technology, as it aligns with their vision and culture.

Ready to land the job?
Join 28M+ others who've built a resume that works.



