




Hard skills, including expertise in cloud services, containerization, CI/CD pipelines, and scripting languages, are essential for automating processes and ensuring system reliability. These hard skills play a important role in achieving technical objectives.
DevOps Engineer Resume Examples & Templates
Looking to advance your career? Our DevOps engineer resume examples highlight essential skills like automation, collaboration, and cloud management to help you stand out to employers.

by Gabriela Hernandez, Last Updated: January 18, 2026
Hired By:*

- Popular DevOps Engineer Resume Examples
- Resume Template—Easy to Copy & Paste
- Build Your Resume in Minutes
- How to Write a DevOps Engineer Resume Summary
- Showcasing Your Work Experience
- Top Skills to Include on Your Resume
- Resume Format Examples
- Related Engineering Resume Examples
- Frequently Asked Questions
- Should I include a cover letter with my devops engineer resume?
- Can I use a resume if I’m applying internationally, or do I need a CV?
- What soft skills are important for devops engineers?
- I’m transitioning from another field. How should I highlight my experience?
- Where can I find inspiration for writing my cover letter as a devops engineer?
- How should I format a cover letter for a devops engineer job?
Popular DevOps Engineer Resume Examples
Check out our top devops engineer resume examples that showcase critical skills such as automation, cloud computing, and collaboration. These examples can help you effectively highlight your accomplishments and expertise.
Ready to build your ideal resume? Our Resume Builder offers user-friendly templates specifically designed for tech professionals, making it simple to create a standout application.
Recommended
 Customize This Resume
Customize This ResumeEntry-level devops engineer resume
What this resume does well:
This entry-level resume for a DevOps Engineer effectively showcases the applicant's technical skills and practical experiences gained through relevant projects and internships. New professionals in this field must demonstrate their ability to automate processes and improve system performance, highlighting any hands-on experience or certifications that indicate their readiness for the role.
Mid-career devops engineer resume
What this resume does well:
This resume effectively showcases the applicant's qualifications by detailing significant achievements in DevOps roles. The clear progression from systems integration to cloud operations highlights their readiness for advanced responsibilities, demonstrating a strong capacity for innovation and efficiency improvements.
Experienced devops engineer resume
What this resume does well:
This resume illustrates a highly skilled devops engineer with significant achievements, such as reducing server costs by 20% and improving CI/CD pipeline efficiency by 30%. The bullet-point format effectively highlights key accomplishments for quick reference, making it ideal for technical hiring managers.
Resume Template—Easy to Copy & Paste
Example
Yuki Lee
Cincinnati, OH 45203
(555)555-5555
Yuki.Lee@example.com
Professional Summary
Experienced DevOps Engineer skilled in pipeline optimization, cloud automation, and system integration. Proven track record in boosting efficiency and reducing costs, adept in utilizing cutting-edge technology solutions.
Work History
DevOps Engineer
ComputeTech Innovations - Cincinnati, OH
April 2024 - October 2025
- Optimized CI/CD pipeline by 30%
- Reduced system downtime by 15%
- Enhanced deployment efficacy by 20%
Cloud Automation Specialist
Cloud Solutions Corp - Cleveland, OH
January 2022 - March 2024
- Automated server provisioning by 40%
- Increased cloud resource usage by 25%
- Integrated monitoring tools 15% faster
Systems Integration Engineer
TechForce Innovations - Cleveland, OH
June 2021 - December 2021
- Integrated 5+ systems in 6 months
- Reduced data transfer latency by 10%
- Improved system interoperability 15%
Languages
- Spanish - Beginner (A1)
- French - Beginner (A1)
- German - Beginner (A1)
Skills
- CI/CD Pipeline
- Cloud Automation
- Systems Integration
- Docker & Kubernetes
- Linux Administration
- Scripting & Automation
- Network Security
- Infrastructure as Code
Certifications
- Certified Kubernetes Administrator - Cloud Native Computing Foundation
- AWS Certified DevOps Engineer - Amazon Web Services
Education
Master of Science Computer Science
Stanford University Stanford, California
June 2021
Bachelor of Science Information Technology
University of California, Berkeley Berkeley, California
June 2019
Build Your Resume in Minutes
Creating a custom resume is easier than ever with our Resume Builder!

How to Write a DevOps Engineer Resume Summary
Your resume summary is the first section hiring managers will see, making it important to create a powerful impression that showcases your qualifications. As a DevOps engineer, you should emphasize your technical skills and experience in automation, cloud services, and collaboration across teams. To help clarify what makes an effective summary, we’ll look at some examples that illustrate successful approaches for this role:
Weak Example
I am a dedicated DevOps engineer with several years of experience in the field. I’m looking for a job where I can apply my skills and contribute meaningfully to the company. A role that offers career advancement and a supportive environment is important to me. I believe I can make a positive impact if given the chance.
Why this summary misses the mark:
- Contains vague phrases about experience without detailing specific skills or achievements
- Overuses personal language, which detracts from professional tone and clarity
- Emphasizes what the applicant desires from the position instead of highlighting their value and contributions to potential employers
Strong Example
Results-driven DevOps Engineer with 6+ years of experience in automating deployment pipelines and optimizing cloud infrastructure. Achieved a 30% reduction in deployment time through implementing CI/CD practices and containerization using Docker and Kubernetes. Proficient in AWS, Terraform, and scripting languages such as Python and Bash, enabling seamless collaboration between development and operations teams to improve system reliability.
Why this summary works:
- Begins with clear years of experience and specific focus areas within DevOps
- Highlights quantifiable achievements that demonstrate tangible improvements in process efficiency
- Showcases relevant technical skills that align with industry demands for a DevOps role
Pro Tip
If you’re new to the field of DevOps and feel short on experience, consider using a career objective. This can effectively showcase your aspirations and skills. To guide you, look for tailored resume objective examples specific to the DevOps role.
Showcasing Your Work Experience
The work experience section is important for your resume as a devops engineer, representing the bulk of your content. Good resume templates always emphasize this essential section to help you stand out.
This area should be organized in reverse-chronological order, clearly listing your previous roles. Use bullet points to highlight key achievements and contributions you've made in each position.
Now, let's examine a couple of examples that illustrate effective work history entries for devops engineers. These examples will clarify what resonates with hiring managers and what pitfalls to avoid:
Weak Example
DevOps Engineer
Tech Solutions Inc. – Austin, TX
- Managed cloud infrastructure.
- Collaborated with teams on projects.
- Automated processes.
- Resolved server issues as they arose.
Why this work experience section misses the mark:
- Lacks specific employment dates
- Bullet points are too vague and do not highlight significant achievements
- Focuses on basic responsibilities rather than measurable impacts or results
Strong Example
DevOps Engineer
Tech Innovations Inc. – San Francisco, CA
March 2020 - Current
- Automated deployment processes using Jenkins and Docker, reducing release time by 40%.
- Implemented monitoring solutions with Prometheus and Grafana, leading to a 30% decrease in system downtime.
- Collaborated with development teams to improve CI/CD pipelines, improving code quality and delivery speed.
Why this work experience section works:
- Starts each bullet point with strong action verbs that highlight the applicant’s contributions
- Incorporates metrics to quantify achievements, demonstrating tangible results
- Showcases relevant technical skills essential for a DevOps role
While your resume summary and work experience are important components, don’t overlook the significance of other sections that contribute to a standout application. For further insights on how to write a resume, explore our detailed guide.
Top Skills to Include on Your Resume
Including a skills section on your resume is important because it provides a quick snapshot of your qualifications. This section allows hiring managers to immediately identify whether you possess the technical skills essential for the role.
As a devops engineer, it's important to highlight both technical and soft skills. You should include expertise in tools like Docker, Kubernetes, Jenkins, and cloud platforms such as AWS or Azure to demonstrate your skill in the field.
Soft skills, such as collaboration, problem-solving, and adaptability, are important for fostering teamwork and effectively addressing challenges in dynamic tech environments.
Selecting the right resume skills is important for aligning with what employers expect from applicants. Many organizations use automated screening tools to filter out applicants who lack essential qualifications for the role.
To improve your chances of getting noticed, carefully review job postings to identify key skills that recruiters highlight. Prioritizing these skills in your resume not only appeals to hiring managers but also helps you pass through ATS screenings successfully.
Pro Tip
Boost your resume’s chances of getting noticed by using our ATS Resume Checker. This tool identifies over 30 common errors, ensuring that your resume successfully bypasses applicant tracking systems.
10 skills that appear on successful devops engineer resumes
Make your resume stand out to recruiters by highlighting the essential skills that are in high demand for DevOps engineers. You can see these skills effectively showcased in our resume examples, which will help you approach job applications with confidence.
Here are 10 skills you should consider including in your resume if they align with your qualifications and job criteria:
Continuous integration/continuous deployment (CI/CD)
Containerization (Docker, Kubernetes)
Cloud computing (AWS, Azure, GCP)
Infrastructure as Code (IaC)
Scripting languages (Python, Bash)
Monitoring and logging tools
Collaboration and communication
Problem-solving abilities
Version control systems (Git)
Automation tools
Based on analysis of 5,000+ engineering professional resumes from 2023-2024
Resume Format Examples
Selecting the appropriate resume format is important for a DevOps engineer, as it highlights your technical skills, project experience, and career growth in a clear and compelling manner.
Entry-Level 0 - 2 years
Functional
Focuses on skills rather than previous jobs
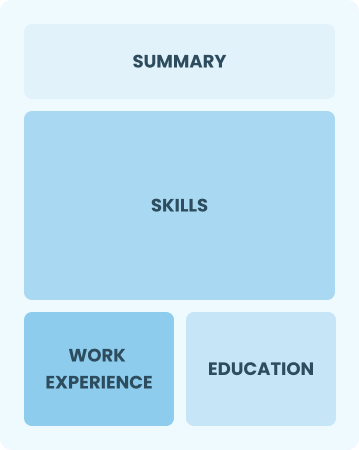
Best for:
Recent graduates and career changers with up to two years of experience
Mid-Career 3 - 7 years
Combination
Balances skills and work history equally
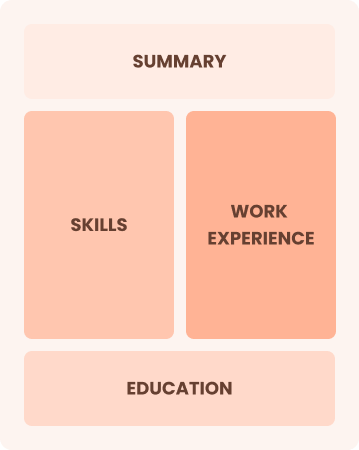
Best for:
Mid-career professionals focused on demonstrating their skills and growth potential
Experienced 8+ years
Chronological
Emphasizes work history in reverse order

Best for:
Seasoned experts driving transformative DevOps initiatives and team leadership
Frequently Asked Questions
Should I include a cover letter with my devops engineer resume?
Absolutely, including a cover letter can significantly improve your application by highlighting your unique qualifications and enthusiasm for the position. It gives you a chance to connect with the hiring manager on a personal level. If you need assistance crafting your cover letter, explore our comprehensive guide on how to write a cover letter or use our easy-to-navigate Cover Letter Generator for quick results.
Can I use a resume if I’m applying internationally, or do I need a CV?
When applying for jobs outside the U.S., use a CV instead of a resume as many employers prefer this format. To help you create an effective CV, explore our CV examples and guides that detail proper formatting and essential elements tailored for international applications. Additionally, learn more about how to write a CV to ensure your application stands out.
What soft skills are important for devops engineers?
Soft skills like communication, collaboration, interpersonal skills, and problem-solving are essential for devops engineers. These abilities enable effective interaction with team members and stakeholders, fostering a culture of continuous improvement and innovation that improves project success.
I’m transitioning from another field. How should I highlight my experience?
Highlight your transferable skills, such as teamwork, analytical thinking, and adaptability. Even if you lack direct DevOps experience, showcasing these abilities demonstrates your potential to excel in the role. Share specific examples from your previous jobs to illustrate how you've successfully tackled challenges that align with DevOps responsibilities and practices.
Where can I find inspiration for writing my cover letter as a devops engineer?
For aspiring DevOps engineers, exploring professionally crafted cover letter examples can be invaluable. These samples offer inspiration for your application materials, providing insight into effective formatting and showcasing your qualifications in a compelling manner.
How should I format a cover letter for a devops engineer job?
To format a cover letter for DevOps engineer positions, start with your contact information and a professional greeting. Then, introduce yourself engagingly by highlighting your passion for the role. Make sure to include relevant qualifications and experience, aligning your content with the job description. Conclude with a strong closing statement that encourages further discussion about how well you fit the position.

Ready to land the job?
Join 28M+ others who've built a resume that works.



